Getting Started
Using Marathon
- Application Basics
- Application Deployments
- Application Groups
- Authorization and Access Control
- Blue-Green Deployment
- Constraints
- Event Bus
- Health Checks
- Marathon Web Interface
- Networking
- Pods
- Recipes
- Provisioning Containers
- Stateful Applications Using Local Persistent Volumes
- Stateful Applications Using External Persistent Volumes
- Task Environment Variables
- Task Handling
- Task Handling Configuration
- Secret Configuration
- Unreachable Strategy
Administration
- Command Line Flags
- Backup and Restore
- Data Migration
- Framework Authentication
- High Availability
- Metrics
- Deprecated Metrics
- Readiness Checks
- Checks
- Service Discovery and Load Balancing
- SSL and Basic Authentication
- Seccomp
- Using a Private Docker Registry
- Maintenance mode
- Compatibility with Mesos
Upgrading
- Upgrading to a new Version
- Migrating Apps to the 1.5 Networking API
- Migrating Tools to the 1.5 Networking API
- Versioning
Troubleshooting
- Stuck App or Pod Deployments
- No new instances are starting
- An App Requires a Specific Host Port
- Error Using HTTPS with local CA Certificate
- Error Reading Authentication Secret
- Slow Docker apps and deployments
- Exit Codes
Development
- Contributor Guidelines
- Current Marathon Development
- Extend Marathon with Plugins
- Run a Local Version of Marathon
API Reference
Docs for Previous Versions
Health Checks and Task Termination
Health checks may be specified per application to be run against that application’s tasks.
- The default health check employs Mesos’ knowledge of the task state
TASK_RUNNING => healthy. - Marathon provides a
healthmember of the task resource via the REST API, so you can add a health check to your application definition.
A health check is considered passing if (1) its HTTP response code is between
200 and 399 inclusive, and (2) its response is received within the
timeoutSeconds period. If a task fails more than maxConsecutiveFailures
health checks consecutively, that task is terminated.
Mesos-level health checks versus Marathon-level health checks
Marathon offers the following protocols for health checks. Declaring a protocol is optional: the default is HTTP.
HTTPHTTPSTCPCOMMANDMESOS_HTTPMESOS_HTTPSMESOS_TCP
Marathon-level health checks
Marathon-level health checks (HTTP, HTTPS, and TCP) are executed by Marathon and thus test reachability from the current Marathon leader. Marathon-level health checks have several limitations:
-
Marathon-level health checks create extra network traffic if the task and the scheduler are run on different nodes (this is usually the case).
-
Network failures between the task and the scheduler, and port mapping misconfigurations can make a healthy task look unhealthy.
-
Marathon-level health checks have
delaySecondsdefined for parity with Mesos-level but have NOT been implemented. -
If Marathon is managing a large number of tasks, performing health checks for every task can cause scheduler performance issues.
-
Marathon-level health checks can’t be used with pods.
These limitations may be acceptable for smaller clusters with low-scale tasks, but Marathon-level health checks should not be used on large clusters with highly scaled Marathon tasks.
Important: Marathon-based health checks are deprecated and will be removed in a future version. See the 1.4.0 release notes for more information.
Mesos-level health checks
Mesos-level health checks (MESOS_HTTP, MESOS_HTTPS, MESOS_TCP, and COMMAND) are locally executed by Mesos on the agent running the corresponding task and thus test reachability from the Mesos executor. Mesos-level health checks offer the following advantages over Marathon-level health checks:
-
Mesos-level health checks are performed as close to the task as possible, so they are are not affected by networking failures.
-
Mesos-level health checks are delegated to the agents running the tasks, so the number of tasks that can be checked can scale horizontally with the number of agents in the cluster.
Limitations and considerations
-
Mesos-level health checks consume extra resources on the agents; moreover, there is some overhead for fork-execing a process and entering the tasks’ namespaces every time a task is checked.
-
The health check processes share resources with the task that they check. Your application definition must account for the extra resources consumed by the health checks.
-
Mesos-level health checks require tasks to listen on the container’s loopback interface in addition to whatever interface they require. If you run a service in production, you will want to make sure that the users can reach it.
-
Marathon currently does NOT support the combination of Mesos and Marathon level health checks.
COMMAND health checks
You must escape any double quotes in your commands. This is required because Mesos runs the healthcheck command inside via /bin/sh -c "".
See the example below and MESOS-4812 for details.
Health Lifecycle
The application health lifecycle is represented by the finite state machine in figure 1 below. In the diagram:
iis the number of requested instancesris the number of running instanceshis the number of healthy instances
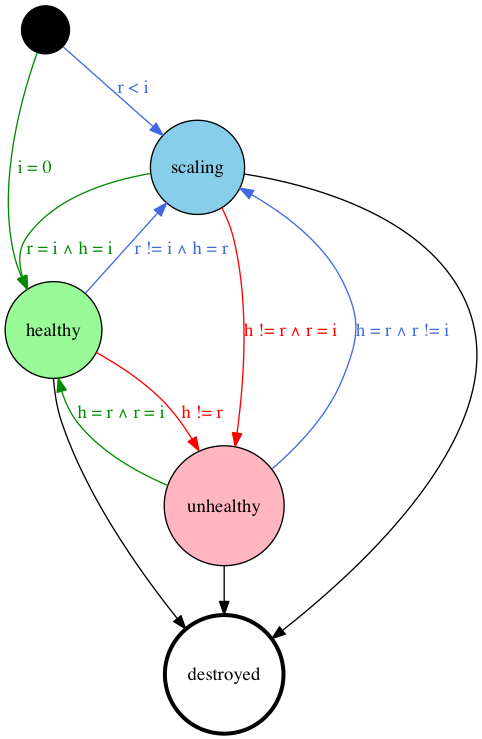
Figure 1: The Application Health Lifecycle
Configure health checks
Declare health checks in the healthChecks parameter of your application definition.
Health check options
Options applicable to every protocol:
gracePeriodSeconds(Optional. Default: 300): Health check failures are ignored within this number of seconds or until the task becomes healthy for the first time.intervalSeconds(Optional. Default: 60): Number of seconds to wait between health checks.maxConsecutiveFailures(Optional. Default: 3): Number of consecutive health check failures after which the unhealthy task should be killed. HTTP & TCP health checks: If this value is0, tasks will not be killed if they fail the health check. Note that this semantic is different for mesos health checks e.g.MESOS_HTTP. Here the task will be killed by mesos after failing>= maxConsecutiveFailurestimes. This means that settingmaxConsecutiveFailures = 0will lead to task being killed immediately after first health check fails.timeoutSeconds(Optional. Default: 20): Number of seconds after which a health check is considered a failure regardless of the response.
For MESOS_HTTP, MESOS_HTTPS, MESOS_TCP, TCP, HTTP and HTTPS
health checks, either port or portIndex may be used. If none is
provided, portIndex is assumed. If port is provided, it takes
precedence overriding any portIndex option.
portIndex(Optional. Default: 0): Index in this app’sportsorportDefinitionsarray to be used for health requests. An index is used so the app can use random ports, like[0, 0, 0]for example, and tasks could be started with port environment variables like$PORT1.port(Optional. Default: None): Port number to be used for health requests.
The following option applies only to MESOS_HTTP, MESOS_HTTPS, HTTP, and
HTTPS health checks:
path(Optional. Default: “/”): Path to endpoint exposed by the task that will provide health status. Example: “/path/to/health”.
The following options only apply to HTTP and HTTPS health checks:
ignoreHttp1xx(Optional. Default: false): Ignore HTTP informational status codes 100 to 199. If the HTTP health check returns one of these, the result is discarded and the health status of the task remains unchanged.
Example usage
HTTP:
{
"path": "/api/health",
"portIndex": 0,
"protocol": "HTTP",
"gracePeriodSeconds": 300,
"intervalSeconds": 60,
"timeoutSeconds": 20,
"maxConsecutiveFailures": 3,
"ignoreHttp1xx": false
}
or Mesos HTTP:
{
"path": "/api/health",
"portIndex": 0,
"protocol": "MESOS_HTTP",
"gracePeriodSeconds": 300,
"intervalSeconds": 60,
"timeoutSeconds": 20,
"maxConsecutiveFailures": 3
}
or secure HTTP:
{
"path": "/api/health",
"portIndex": 0,
"protocol": "HTTPS",
"gracePeriodSeconds": 300,
"intervalSeconds": 60,
"timeoutSeconds": 20,
"maxConsecutiveFailures": 3,
"ignoreHttp1xx": false
}
Note: HTTPS health checks do not verify the SSL certificate.
or TCP:
{
"portIndex": 0,
"protocol": "TCP",
"gracePeriodSeconds": 300,
"intervalSeconds": 60,
"timeoutSeconds": 20,
"maxConsecutiveFailures": 0
}
or COMMAND:
{
"protocol": "COMMAND",
"command": { "value": "curl -f -X GET http://$HOST:$PORT0/health" },
"gracePeriodSeconds": 300,
"intervalSeconds": 60,
"timeoutSeconds": 20,
"maxConsecutiveFailures": 3
}
{
"protocol": "COMMAND",
"command": { "value": "/bin/bash -c \\\"</dev/tcp/$HOST/$PORT0\\\"" }
}
Task Termination
TASK_KILLING
TASK_KILLING is a task state that signals that a task has received a kill request and is in the grace period. Other tools, for instance a load balancer or service discovery tool, should not route traffic to tasks in that state.
The task_killing feature must be enabled in order to make the state available. See the Command Line Flags documentation for details.
taskKillGracePeriodSeconds
While health checks allow you to determine when a task is unhealthy and should be terminated, the taskKillGracePeriodSeconds field allows you to set the amount of time between when the executor sends the SIGTERM message to gracefully terminate a task and when it kills it by sending SIGKILL. This field can be useful if you have a task that does not shut down immediately. If you do not set a kill grace period duration, then no value is provided to Mesos.
Example
The following long-running service needs a grace period of at least 6 seconds:
#!/bin/bash
# A signal handler to shut down cleanly.
# Shutdown takes at least 6 seconds! The grace period should be set higher than this.
function terminate {
echo $(date) Marathon requested shutdown, stopping the DB
sleep 3
echo $(date) Cleaning up disk
sleep 3
echo $(date) All done, exiting cleanly
exit 0
}
# catch TERM signals
trap terminate SIGTERM
echo $(date) Long-running service running, pid $$
while true; do
sleep 1
done
To set the necessary grace period, add the taskKillGracePeriodSeconds field to your application definition:
{
"id": "/foo",
"instances": 2,
"cmd": "sleep 1000",
"cpus": 0.1,
"disk": 0,
"mem": 16,
"labels": {
"owner": "zeus",
"note": "Away from olympus"
},
"taskKillGracePeriodSeconds": 30
}