This is a “getting started” guide for running multiple services from a single SDK-based Scheduler process/Framework, with support for dynamically adding or removing those services from the Scheduler without needing to restart it.
Readers of this document should already have some experience with writing SDK-based services. It assumes that the reader has some knowledge/experience with high-level SDK concepts, such as ServiceSpecs and AbstractSchedulers.
Everything here is subject to change. There may be bugs or deficiencies in the current implementation as described here, and there may need be API changes before this feature will be ready for use in a production situation. But please send feedback! And patches!
If you’re looking for example usage, just take a look at the reference implementation in hello-world. In particular, the ‘Dynamic Multi-Service’ example should be applicable to most people. It also has integration tests. In addition to that, most of the SDK code involved in this change resides in the SDK’s scheduler.multi package.
Overview
A Multi-Service Scheduler is effectively a single Mesos Framework/Scheduler process, which manages multiple underlying Services. A “Service” is represented by a single ServiceSpec (and associated Plans), which are wrapped in an AbstractScheduler object, potentially with other customizations provided by the developer.
Terminology
- Framework: A client of Mesos which receives Offers and TaskStatus messages and performs Mesos Operations in the cluster.
- Service: Something that’s being run by the cluster via commands to Mesos. The “payload” that a user wants to run, effectively.
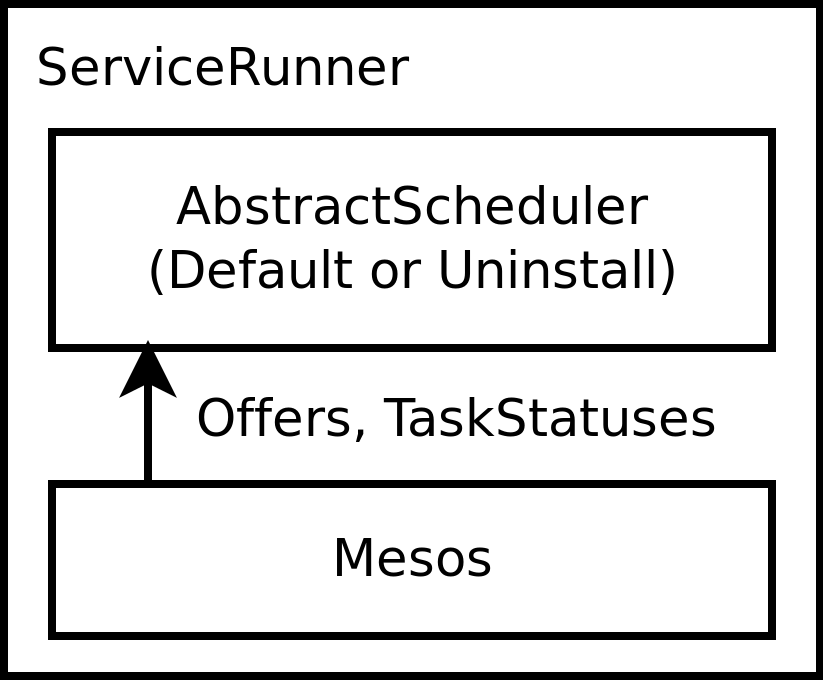
- Mono-Scheduler: A process which connects to Mesos as a single Framework and which operates a single hardcoded (but configurable) Service for its entire lifetime.
- Multi-Scheduler: A process which connects to Mesos as a single Framework but which runs zero or more Services, which at runtime can be dynamically added/removed.
Existing Data Services
In practice, existing data services (Kafka, Cassandra, etc.) will continue to use the Mono-Scheduler structure for the foreseeable future, for the following reasons:
- Each of those services requires distinct custom logic implemented in Java, so having a single Scheduler running multiple types of data services would be complicated.
- Production database users would want to manage multiple instances fully independently, with different versions of the software on each. It’s therefore more straightforward (and safer) to just keep the management layer separate as well.
- In particular, separate management of each database instance allows e.g. a prod instance which is upgraded fully independently from a test/staging instance.
Limitations
The following are known limitations of this Multi-Schedulers:
- A multi-service Scheduler instance is still only operating a single Framework from Mesos’ perspective, so anything that has to vary on a per-Framework basis will require multiple Scheduler instances.
- Similarly, the Framework is registered up-front on Scheduler startup, so changing Framework-level parameters such as registered roles would involve restarting the Scheduler process. This shouldn’t be an issue in practice as the Scheduler is designed to be permissive of periodic restarts, but there’s nothing saying that live re-registration couldn’t be implemented, either.
- Existing instances of Mono-Scheduler services can be migrated to Multi-Scheduler services with few limitations:
- Migration is currently unidirectional. Once the service is upgraded to Multi-Scheduler, it cannot go back to being a Mono-Scheduler.
- Multi-service support requires a new ZK layout where Service-specific data is grouped into per-Service subnodes, this is treated as a new SchemaVersion value of
2. - Migration can only happen when using the Multi-Service Scheduler in its “Static” mode (discussed later in this document). This is due to the fact that if we try to migrate from a Mono-Scheduler to Multi-Scheduler in Dynamic mode then there is a time period for the new Multi-Scheduler with 0 services but it receives offers, task statuses etc. from Mesos and it does not know what to do with them. For this reason, migration is supported only from Mono-Scheduler to Multi-Scheduler in its static mode.
- We do a timestamped backup of all the ZooKeeper Nodes which are to be migrated. Currently there is no recovery path if the migration fails. However, the user can manually restore the ZK backup nodes and reset the Store Schema Version accordingly.
- Multi-service support requires an additional
namespacelabel in Mesos resource reservations, so that resources can be mapped back to the service they belong to. Multi-service support requires thatTaskIDs contain the service name, so that e.g.TaskStatuses can be routed to the correct service. Therefore, Old single-service tasks cannot recognized by a new multi-service scheduler unless they have anamespacelabel. All tasks launched with newer versions of the SDK (0.50+) will include this, even with mono-schedulers. - When migrating to a new Multi-Scheduler, user should ensure that there is a service with the same name as the framework name of the old Mono-Scheduler. This is because when making reservations or launching tasks in the Mono-Scheduler, the
servicename(whose value is equal to framework name in Mono-Scheduler world) is used in the labels. After the migration completes, thenamespaceis needed to match the name of the service it belongs to.
Requirements
In order to build a Multi-Service Scheduler, the developer needs to implement a few things themselves:
- A serialized format for the per-service config. This config must have the necessary information to rebuild your
AbstractSchedulerobjects if/when the Scheduler is restarted. - A
ServiceFactorycallback which will use that serialized config to build services viaSchedulerBuilder. - When building the service using
SchedulerBuilder, callenableMultiService(String frameworkName). - If services are supposed to be added/removed by end users, any HTTP endpoints or similar functionality needed to support those calls must be implemented by the developer.
Keep reading for more information on each of those points, with links to examples.
Config serialization and ServiceFactory implementation
If the Scheduler process is restarted, any previously added services must be re-added so that they can resume running. In order for the SDK to do this, the developer needs to provide a ServiceFactory callback which will recreate the AbstractScheduler object when invoked. This callback is provided with a byte[] context field, where any application-specific information needed to reconstruct a given service can be stored. To use this context field, the service developer must implement a serialization format for config. For example, this could be used to store a small JSON blob storing application-level information about the service’s configuration.
-
Hello-worldincludes a sample implementations ofServiceFactory, which uses a JSON serialization format. It’s recommended that your context be a 1:1 mapping of the input data provided by the user. Then you don’t have any issues with losing user intent as they upgrade your service. - Note: Things are done this way because we allow developers to insert arbitrary Java logic/objects into their service when constructing it. This makes it difficult for the SDK to automatically serialize/persist these customizations on the SDK’s end. Having the developer provide their own callback in this way allows them to continue injecting their own customizations into services, while also allowing the service objects to be consistently rebuilt across scheduler restarts.
Call SchedulerBuilder.enableMultiService()
Within that ServiceFactory callback, the developer should use a SchedulerBuilder to build the AbstractScheduler object, as they would do with single-service schedulers today. However, the developer must also be careful to invoke SchedulerBuilder.enableMultiService(String frameworkName) to enable multi-service support within the service being built. Hello-world has an example of a ServiceFactory implementation.
HTTP Endpoint(s) (optional)
If the developer intends for end-users to add/remove services from the Scheduler, the developer must implement their own HTTP endpoint(s) which do this. The exact functionality of these endpoints depends on the specific service being implemented. For example, a Spark Dispatcher implementation could include an endpoint that emulates the spark-submit endpoint, which internally adds the submitted jobs as new services. For example, this endpoint in the hello-world reference implementation accepts an example YAML template filename to be run and any parameters to use with it.
Implementation
Here are the main components to know about when building a Multi-Service Scheduler.
There are four new classes in the SDK to be aware of:
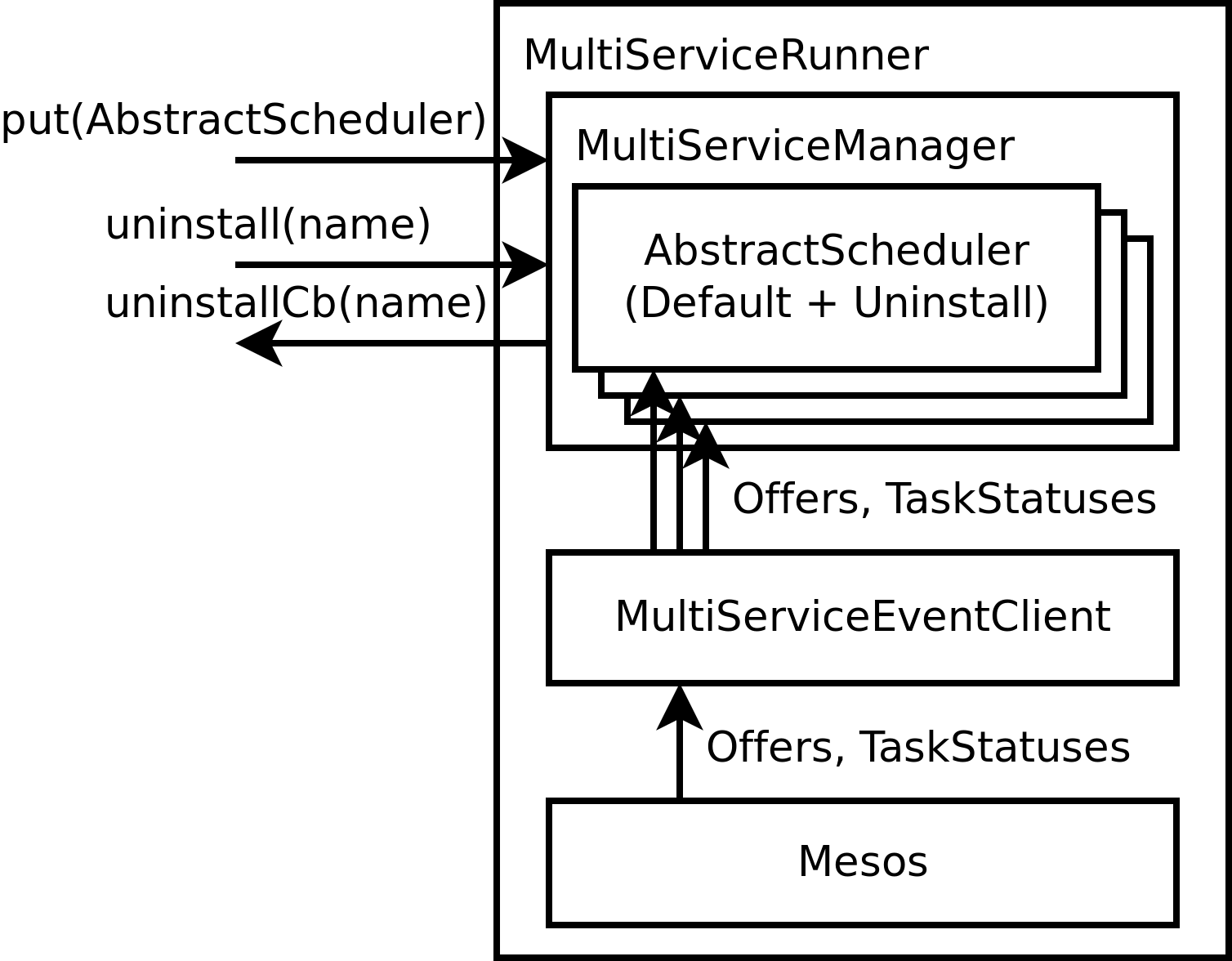
- MultiServiceManager: In-memory management of running services. Adding/removing services by developers is done here.
- ServiceStore: Persists information about running services to ZK so that they are remembered across scheduler restarts. As mentioned in the Requirements above, the developer only needs to provide a callback which will rebuild service objects, given a buffer of developer-defined context data.
-
MultiServiceEventClient: Routes Mesos events (
Offers,TaskStatuses, etc) to individual services which are stored within theMultiServiceManager. For example, this routes a receivedTaskStatusto the service which owns that task. -
MultiServiceRunner: Runs the main Framework thread, passing events from Mesos to a provided
MultiServiceEventClient.MultiServiceRunnermirrors today’sServiceRunnerused by Mono-Schedulers.
| Single-service structure | Multi-service structure |
|---|---|
 |
 |
Given these classes, there are three things you’d want to implement:
- Your
main()function, which creates/initializes the above three classes, and then invokesMultiServiceRunner.run()to start the Framework thread. - A callback which will rebuild any active services which were previously added via
MultiServiceManager.putService(). If you have a fixed/static list of services to add, then this is very simple, since you’d just re-add the same list of services every time the scheduler starts. Otherwise, you would use aServiceStoreto handle persisting the services while they’re active, along with aServiceFactorycallback which would be used by the SDK to rebuild the services upon restart. - Any application-specific logic for dynamically adding/updating/removing services in the list, For example this could be HTTP endpoints which would result in calling
MultiServiceManager.putService()/uninstallService(), after having updated the list of active services in the developer’s persisted storage (see previous requirement). This logic is only needed if the list of services can change on the fly – a fixed set of services would not need this.
Example flows
The following describe the steps to perform common operations in a Multi-Scheduler. To see a full reference implementation supporting all of these operations, take a look at the additions to hello-world in this dcos-commons PR.
Adding a Service
Adding a service to a Multi-Scheduler works as follows:
- Somebody (e.g. end user via HTTP endpoint, or hardcoded in Main) notifies the scheduler process that a service should be added.
- The
AbstractSchedulerobject is built via theServiceFactorywithinServiceStore. This has the side effect of persisting the service context to ZK so that it can be reconstructed on scheduler restart.- The SDK invokes the developer’s
ServiceFactoryon initial service construction in order to ensure that the submitted data works at least once before it’s persisted. - The developer’s
ServiceFactorywill internally use aSchedulerBuilder, being careful to callSchedulerBuilder.enableMultiService().
- The SDK invokes the developer’s
- The constructed
AbstractScheduleris then added to the set of running services usingMultiServiceManager.putService(). TheMultiServiceManageradds the service to its internal map, andMultiServiceEventClientautomatically starts sending MesosOffers to it. The service uses thoseOffers to deploy as usual.
Reconfiguring a Service
Updating the configuration of existing services which were previously added is also supported. The flow for doing this in a Multi-Scheduler works as follows:
- A new version of the service is constructed via the
ServiceStoreandServiceFactoryas described in Adding a Service above, with a new service name that exactly matches the previous version’s service name. - When this new version of the service is added to the
MultiServiceManager, it automatically replaces the previous version. - The new version of the service starts getting Offers and internally goes through the same config update flow that a normal single-service scheduler would go through, redeploying the underlying nodes of the service as needed to reflect the config change.
Restarting the Scheduler
In the event of a Scheduler process restart, the Scheduler will automatically reconstruct the active services as it’s initialized. This reconstruction is done using the ServiceFactory provided by the developer.
- The scheduler process is restarted for some reason, e.g. agent failure or config change.
- The developer’s
main()function should construct aServiceStorewith a developer-implementedServiceFactory, and then invokeServiceStore.recover(). -
ServiceStore.recover()will return a list of recoveredAbstractSchedulers which were reconstructed via theServiceFactory. These should each be passed toMultiServiceManager.putService(AbstractScheduler). - Each of the added services will automatically re-initialize and pick up where they left off before the restart.
Removing a Service
Service removal is handled asynchronously. The developer requests that a service be removed, and it gets removed in the background (killing that service’s tasks and unreserving its resources). The developer is notified via a callback when the removal is complete:
- Somebody (e.g. end user via HTTP endpoint) invokes
MultiServiceManager.uninstallService(String), with the argument being the name of a service previously added viaputService(). SeeServiceSpec.getName(). - Internally, the previously-added
AbstractSchedulerfor this service is converted to anUninstallScheduler, which starts tearing down the service. In the meantime the service is still considered added and running, and should still be re-added if the Scheduler is restarted (at which point uninstall will automatically resume).- By default, service removals taking more than 10 minutes will be force-completed. In practice, this should only happen when e.g. an agent containing some resources is offline and previously-reserved resources from that agent are not being re-offered. If these resources are reoffered later, they will be automatically cleaned up via the SDK’s default garbage collection behavior.
- Finally, after the service has finished its teardown, a developer-provided
UninstallCallbackwill be invoked, telling upstream that the service has been fully removed. In practice, this callback should have been obtained from theServiceStore. This default callback implementation will remove the uninstalled service from theServiceStore. The developer may implement their own custom callback which also performs other work, but the service should always be removed from theServiceStorewhen it’s complete, otherwise it will just be recovered later on.
Uninstalling the Scheduler
Uninstalling the scheduler (i.e. via dcos package uninstall ...) works as follows. This effectively works by unwinding all previously-added services, and then removing the parent framework and main Scheduler process once all services have been torn down:
- As with any SDK-based package, the scheduler process is restarted with an
SDK_UNINSTALL=trueenvvar added by Cosmos. This is the hint to the SDK that it should tear everything down. - As with any Scheduler restart, the SDK will recover any previously running Services by calling
ServiceStore.recover()and then passing the results toMultiServiceManager.putService(AbstractScheduler). - As the services are each constructed by
SchedulerBuilder, the globalSDK_UNINSTALLenvvar will be detected automatically, and the services will automatically be built in uninstall mode. As a result, the services will automatically start tearing down in parallel as they’re added toMultiServiceManager.- Unlike with service removal, there is no timeout for per-service when the whole scheduler is being uninstalled. This is because there will be no opportunity to garbage-collect leftover resources at this point.
- After all the services have finished teardown, the scheduler process will see that nothing is left to be torn down. The Framework will be deregistered from Mesos and the Scheduler process will advertise completion to Cosmos.
- Cosmos will then detect the completion and remove the Scheduler app from Marathon, finishing the uninstall.