Getting Started
Using Marathon
- Application Basics
- Application Deployments
- Application Groups
- Authorization and Access Control
- Blue-Green Deployment
- Constraints
- Event Bus
- Health Checks
- Marathon Web Interface
- Networking
- Pods
- Recipes
- Provisioning Containers
- Stateful Applications Using Local Persistent Volumes
- Stateful Applications Using External Persistent Volumes
- Task Environment Variables
- Task Handling
- Task Handling Configuration
- Secret Configuration
- Unreachable Strategy
Administration
- Command Line Flags
- Backup and Restore
- Data Migration
- Framework Authentication
- High Availability
- Metrics
- Deprecated Metrics
- Readiness Checks
- Checks
- Service Discovery and Load Balancing
- SSL and Basic Authentication
- Using a Private Docker Registry
- Maintenance mode
- Compatibility with Mesos
Upgrading
- Upgrading to a new Version
- Migrating Apps to the 1.5 Networking API
- Migrating Tools to the 1.5 Networking API
- Versioning
Troubleshooting
- Stuck App or Pod Deployments
- No new instances are starting
- An App Requires a Specific Host Port
- Error Using HTTPS with local CA Certificate
- Error Reading Authentication Secret
- Slow Docker apps and deployments
- Exit Codes
Development
- Contributor Guidelines
- Current Marathon Development
- Extend Marathon with Plugins
- Run a Local Version of Marathon
API Reference
Docs for Previous Versions
New Core Architecture
We want to move Marathon to a new architecture iteratively. Components that already have been
migrated live in the mesosphere.marathon.core package.
The goals are:
- Use a consistent strategy in dealing with shared mutable state
- Use Actors but only as an implementation detail (see below)
- Propogate creates/updates to durable storage but serve reads from memory
- Make the architecture of Marathon easier to understand and make it easier to replace sub modules.
- Better separation of concerns
- Less coupling
First Step: LaunchQueue
As a first step, we reimplement offer matching and task launching by providing
a new implementation for the LaunchQueue (formerly TaskQueue) and the IterativeOfferMatcher. That means
that some glue code is necessary for a while but it allows us to progress
iteratively.
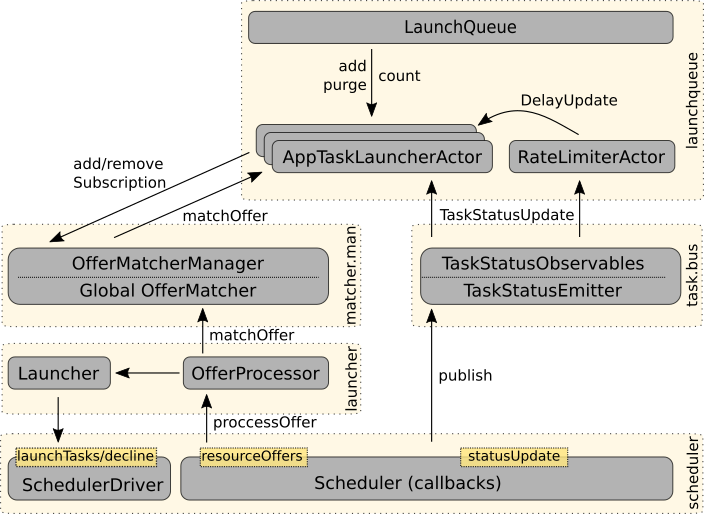
The LaunchQueue manages starting of new tasks. Other parts of Marathon can request launching tasks for a specific
application by calling the add method of the LaunchQueue. For every application, the underlying
LaunchQueueActor creates an AppTaskLauncherActor. These AppTaskLauncherActor subscribe for
resource offers and may match tasks to launch for the received offers. The OfferMatcherManager
distributes the incoming offers along all interested subscribers. When an offer has been completely processed, the
OfferProcessor forwards the result to the Launcher such that the appropriate tasks are launched or the offer
gets rejected. Updates of task state are propagated via the TaskStatusObservables.
Dealing with leadership changes
In the short term, we want to keep our current approach. That means that only the current leader Marathon instance actively processes requests at any time. All other Marathon instances forward requests to the instance.
When all our state is kept in actors, we can use a simple strategy for dealing with leadership changes.
When a Marathon instance gains leadership, it will start all its top-level actors.
When a Marathon instance loses leadership, it will stop
all its top-level actors and thus lose all its non-persisted state. Since there is value in providing ActorRefs which
survive leadership changes, every top-level actor has a proxy which handles the appropriate starts and stops. The
corresponding code is in the mesosphere.marathon.core.leadership package.
Second Step: Move TaskState into Actors
Our information about tasks changes frequently. Thus, it profits most from serving reads from main memory. It is also most prone to concurrency bugs.
What is more, in the LaunchQueue design we have to specify how many additional tasks to launch. Since the task
launcher already has to know about all tasks of an app to satisfy constraints, it make sense to instead
specify an absolute target number of tasks.
Conventions
These conventions guide the refactoring of the code. All code in the core package should follow these convetions.
Actors as an implementation detail
We think that Akka Actors are the most idiomatic way of dealing with shared mutable state in Scala. Unfortunately,
we do not like untyped actor references. Since typed alternatives to ActorRefs are not mature yet,
we restrict interactions with
and between actors to single packages. The functionality of these actors should then be exposed by trait methods,
that also make the intended interaction clear. So we use
- methods returning
Unitfor fire-and-forget interactions - methods returning
scala.concurrent.Futures for request/response interactions - methods returning
rx.lang.scala.Observables for subscriptions to messages streams
This results in more glue code between the modules but expresses the intended interaction patterns clearly.
Restrict visibility
To ensure modularity, we use the Scala private keyword to restrict visibility as much as possible.
Hide implementations in impl packages
To separate the public interface of a package, we provide interface traits at the top-level of a package and
hide implementations of these interfaces in a sub impl package.
Dependency injection
We do like separating wiring code from the rest.
At the same time, we want to get compile time errors for missing or incorrect dependencies.
This is why we perform the wiring in classes called *Module which simply consist of Scala code.
Right now, Marathon still contains cyclic dependencies. We do not encourage that and want to get rid of them
eventually.