Getting Started
Using Marathon
- Application Basics
- Application Deployments
- Application Groups
- Authorization and Access Control
- Blue-Green Deployment
- Constraints
- Event Bus
- Health Checks
- Marathon Web Interface
- Networking
- Pods
- Recipes
- Provisioning Containers
- Stateful Applications Using Local Persistent Volumes
- Stateful Applications Using External Persistent Volumes
- Task Environment Variables
- Task Handling
- Task Handling Configuration
- Secret Configuration
- Unreachable Strategy
Administration
- Command Line Flags
- Backup and Restore
- Data Migration
- Framework Authentication
- High Availability
- Metrics
- Deprecated Metrics
- Readiness Checks
- Checks
- Service Discovery and Load Balancing
- SSL and Basic Authentication
- Using a Private Docker Registry
- Maintenance mode
- Compatibility with Mesos
Upgrading
- Upgrading to a new Version
- Migrating Apps to the 1.5 Networking API
- Migrating Tools to the 1.5 Networking API
- Versioning
Troubleshooting
- Stuck App or Pod Deployments
- No new instances are starting
- An App Requires a Specific Host Port
- Error Using HTTPS with local CA Certificate
- Error Reading Authentication Secret
- Slow Docker apps and deployments
- Exit Codes
Development
- Contributor Guidelines
- Current Marathon Development
- Extend Marathon with Plugins
- Run a Local Version of Marathon
API Reference
Docs for Previous Versions
Marathon Web Interface
The Marathon UI source code repository lives at https://github.com/mesosphere/marathon-ui. For issues and feature requests related to the web UI, please refer to the Support page.
By default, Marathon exposes its web UI on port 8080. This can be configured
via command line flags.
Application Status Reference
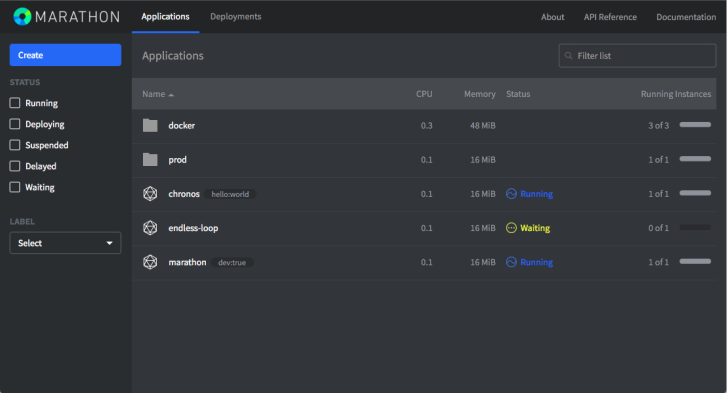
Marathon UI introduces the following concepts to illustrate the possible statuses an app can be in at any point in time:
- Running
- Deploying
- Suspended
- Delayed
- Waiting
These statuses are displayed in the UI’s application list view to provide an at-a-glance overview of the global state to the user.
Following is an explanation of how each status is determined based on certain conditions as exposed by the REST API.
Running
The application is reported as being successfully running.
Deploying
Whenever a change to the application has been requested by the user. Marathon is
performing the required actions, which haven’t completed yet.
True when the v2/apps endpoint returns a JSON response with
app.deployments.length > 0.
Suspended
An application with a target instances of 0 and whose running tasks count is 0.
True when the JSON returned looks like:
app.instances === 0 && app.tasksRunning === 0
Additionally, by inspecting the v2/queue endpoint the following states can
also be determined:
Waiting
Marathon is waiting for offers from Mesos. True whenever an app has
queueEntry.delay.overdue === true.
Delayed
An app is considered delayed whenever too many tasks of the application failed
in a short amount of time. Marathon will pause this deployment and retry later.
True if the queue endpoint returns the following JSON condition:
queueEntry.delay.overdue === false
Application Health Reference
It is possible to specify health checks to be run against an application’s tasks. For instructions on how to set up and use health checks, please refer to the health checks page page.
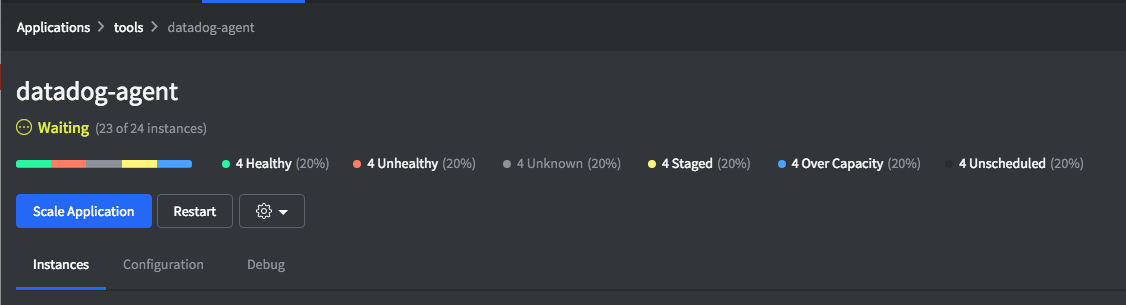
An application’s task lifecycle always falls into one of the following conditions.
Healthy
A task is considered healthy when all of the supplied health checks are passing.
Unhealthy
A task is considered unhealthy whenever one or more health checks are reported as failing.
Staged
A task is staged when a launch request has been submitted to the cluster, but has not been reported as running yet. Fetching the specified “fetch” in the app definition or the docker images happens before Mesos reports the task as running.
Additionally, the UI introduces the following concepts.
Unknown
The health of the task is unknown because no health checks were defined.
Overcapacity
Whenever there are more running tasks than the amount of instances requested. This happens, for example, when a rolling restart is performed with a deployment policy that enforces a draining approach (i.e. new tasks are started before the running ones could be destroyed), or when scaling down.
Unscheduled
Whenever a task never manages to reach the staged status, e.g. when no matching offer has been received, or Marathon throttles starting new tasks to prevent overwhelming Mesos.